
Improved qualitative data management with Advanced Splits
Relative Insight helps businesses get value out of their text data. But data can be a fickle friend and getting it ready for comparison can often take more time than it should. With the suite of tools available in the platform, we are determined to help you improve your qualitative data management.
As part of these efforts, we are excited to launch our newest feature – Advanced Splits. This powerful update to the Data Library helps to solve the challenges of effective data management, making it faster and easier to build your comparisons.
Here’s a rundown of everything you need to know…
What is data splitting?
In Relative Insight, splitting is the ability to subdivide a master data set into smaller components in order to build comparisons.
Splits can be defined based on any data points linked to a text response. For example, you might have a spreadsheet full of survey open ends that you want to group together based on age, rating of your product, location or another attribute. If you’ve uploaded any metadata points along with your text responses, you’ll be able to use the split functionality.
Simplified qualitative data management
While the ability to split data is not new, Advanced Splits greatly reduce the amount of time it takes to get your data ready for comparison.
Consider a situation in which you have a file of survey responses from customers across 20 different countries and you want to compare each country against all others to reveal what makes each market unique.
Previously, you would have to go through the split process 20 times, defining specific rules for each country.
- Country = UK
- Country = USA
- Country = Germany
- ….and so on
With Advanced Splits, you can create a subset for each country (or any other attribute) in one go – saving you time so you can get to the insights quicker.
Using advanced splits
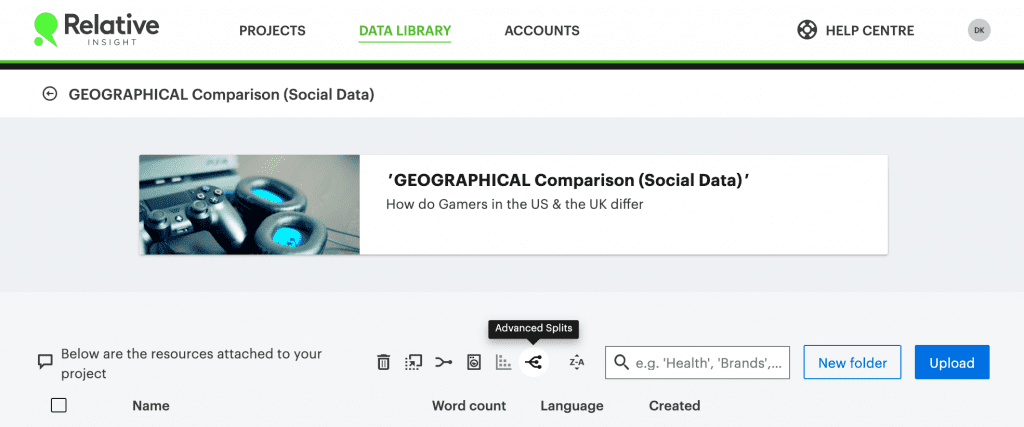
To use advanced splits, navigate to the Data Library. From here, simply select the language set you want to split and click the Advanced Split icon from the action menu at the top of your data list.
You can then specify which pieces of metadata you want to use as the basis for creating your splits. For each attribute selected, a unique data subset will be created that only includes text that is linked to that attribute. A preview of all of your language sets will be provided in the right-hand pane, where you are also able to rename each subset. You can create up to 20 splits at once.
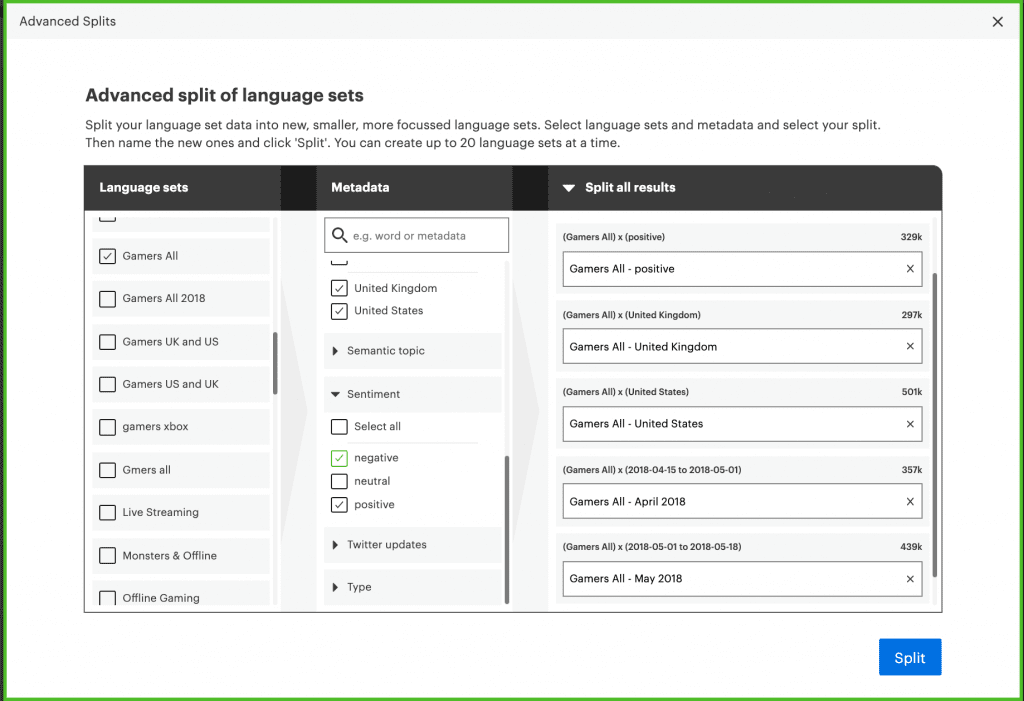
When the right-hand pane is set to ‘Split all results’, a unique language set will be created for each piece of metadata selected. However, Advanced Splits also supports the instant combination of various subsets.
For example, if you have a file of survey data that contains the country of the respondent and you want to create a subset representing North America, you can tick the boxes for Canada, United States and Mexico and then select the arrow to change your setting to ‘Combine all’. This would produce an aggregated language set of responses from those three countries that you could title ‘North America’.
Read our full step-by-step guide on Advanced Splits in our Help Centre.
What’s happening to the current split functionality?
It’s not going anywhere – you can continue to split language sets how you always have!
This also continues to be the best approach when you are wanting to define multiple conditions for a single split. For example, if you wanted to produce a subset of survey responses representing people who are both aged 18-24 AND located in North America this would be the best approach.
